 Computer Forum
Computer Forum
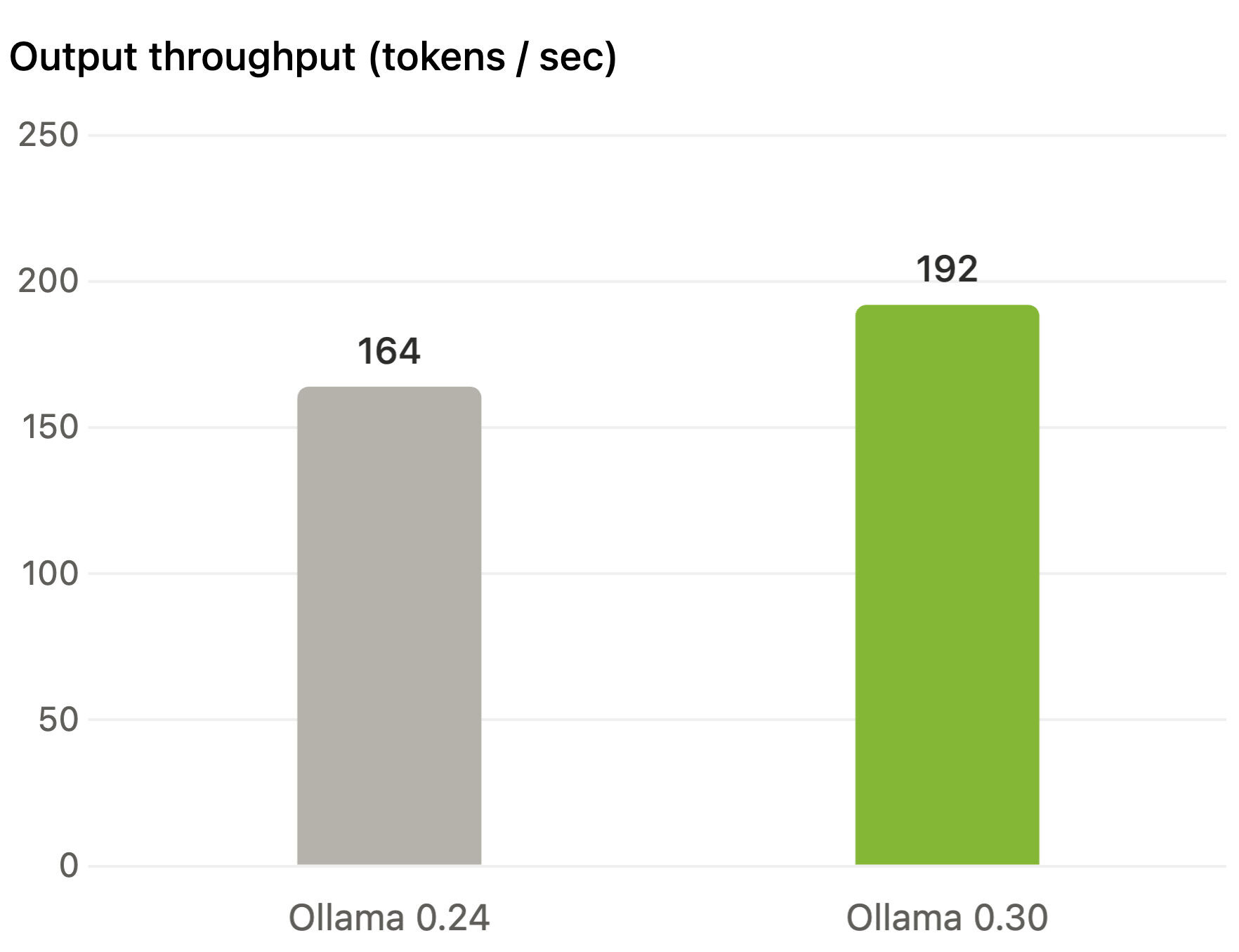 Ollama 0 30 verbessert die GPU Leistung (Image © Ollama)
Ollama 0 30 verbessert die GPU Leistung (Image © Ollama)
Hardware Acceleration and Throughput
The update delivers measurable performance gains for NVIDIA users, with throughput increasing by up to 20%. These improvements are the result of optimizations developed in collaboration with the teams at NVIDIA and llama.cpp. Tests on an NVIDIA RTX 5090 using the Gemma 4 26B model with Q4_K_M quantization confirm these efficiency gains. Beyond NVIDIA, Ollama 0.30 enables Vulkan by default. This change extends GPU acceleration to a wider range of hardware and particularly benefits users with AMD and Intel devices. By leveraging Vulkan, these users can immediately access GPU performance without having to install additional vendor-specific libraries.
Expanded Model Compatibility
Ollama 0.30 increases compatibility within the GGUF ecosystem. This enables the immediate deployment of several new model families, including Prism and LFM, as well as various fine-tuned models released by Unsloth. The update also simplifies the execution of GGUF models sourced from Hugging Face. To implement these models, users can download the GGUF file and use the “FROM” command to create a model file that references the specific file path. Once the model file is configured, the model can be created and run using standard Ollama commands.
Integration of Tool Calls and Coding Assistants
Tool invocation functionality is now fully supported in Ollama, provided the underlying model has the appropriate capabilities. This enables the software to communicate directly with various coding agents and personal assistants.
Supported integrations include Claude Code, Hermes Agent, and OpenClaw, which can be launched via a single command specifying the selected model. To ensure a model is compatible with these agents, users can check the tool-invocation capabilities using the command ollama show.
These developments were made possible through technical collaborations with the maintainers of llama.cpp and hardware partners such as Intel, Qualcomm, AMD, and NVIDIA, with a focus on optimizing the GGML ecosystem across various platforms.
