 Computer Forum
Computer Forum
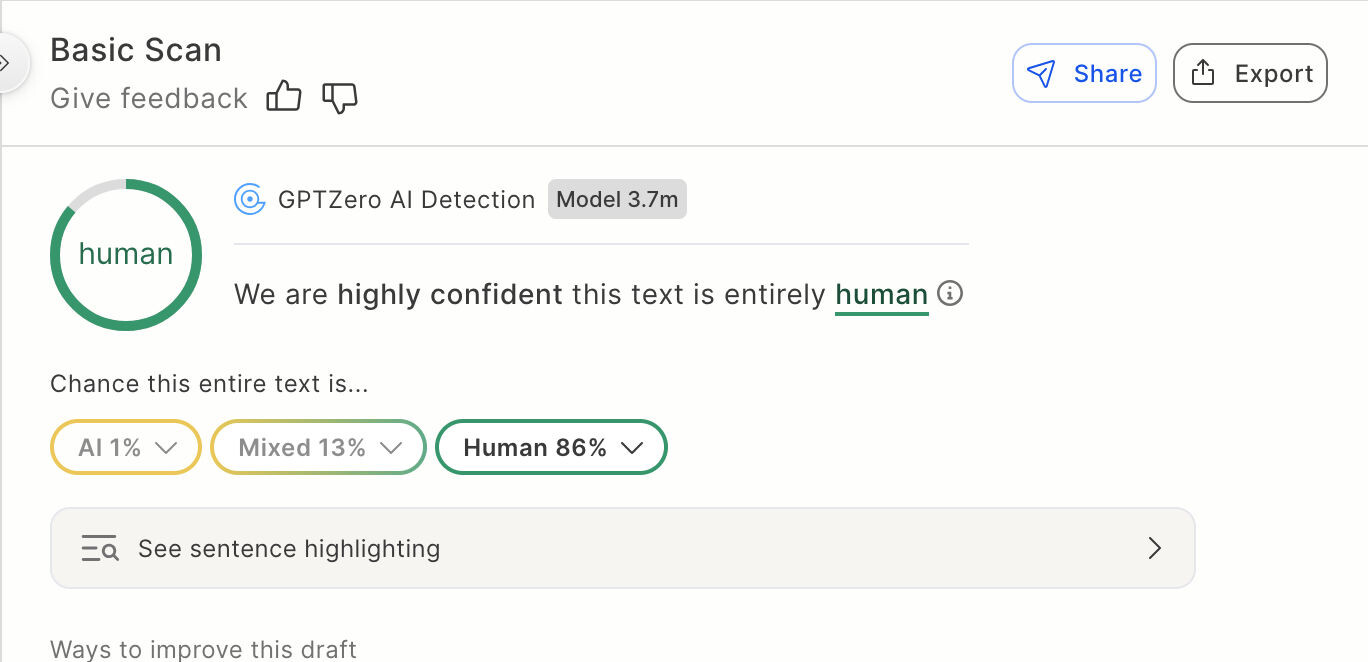 Erkennung von KI Inhalten (Image © PCMasters.de)
Erkennung von KI Inhalten (Image © PCMasters.de)
Recognition of AI content
The technical basis of these scanners is based on statistical analysis, specifically perplexity and burstiness. Perplexity evaluates how predictable a text is; since large language models are designed to select the most likely next word, their output usually has low perplexity. This is why you often hear that LLMs are just the better autocompleteers. Burstiness refers to the variance in sentence structure and length. Human texts are inherently irregular and alternate between short and complex sentences, whereas artificial intelligence tends to maintain a steady, rhythmic rhythm. High-end detectors complement these metrics with neural networks trained to recognize patterns in deep layers.
 Kostenlose KI Detektoren (Image © PCMasters.de)
Kostenlose KI Detektoren (Image © PCMasters.de)
The human in the text
Despite these technical layers, the stylistic markers used to label AI are often ambiguous. Scanners look for a lack of individual perspective, an overly formal tone and a tendency towards parallel sentence structures. In English, certain keywords have become markers for AI, but in other languages this is less effective. For example, the recognition accuracy for German texts is significantly lower, as less training data is available and the linguistic grammar is more complicated.
The most critical point is still the error rate. Studies show that even the most effective scanners work with an accuracy of 70 to 80 percent. This means that around one in four texts is classified incorrectly. Particularly worrying are false positive results where a text written by a human is labeled as AI. The data shows a systematic bias where non-native speakers are more likely to be identified as artificial intelligence, probably because their texts tend to follow rigid or predictable patterns.
Free AI text detectors
For companies and publishers, these inaccuracies change the usefulness of recognition tools. In addition, people also make mistakes and mistype. When it comes to search engine optimization, the current consensus is that platforms like Google prioritize the value and quality of the information provided to the user, rather than whether the content was created using AI. Consequently, it is often less productive to focus on the origin of a text than on its editorial content.
In professional environments, such as when hiring staff or reviewing guest posts, relying solely on AI scanners can lead to poor decisions. Since simple paraphrasing tools can often bypass the recognition functions and human-edited AI texts are almost impossible to distinguish, these tools serve as a general guide rather than definitive proof of authorship. The trend in the industry is towards quality assurance, where the focus is on whether a text is well-researched and useful regardless of its source.
