Computer Forum
Computer Forum


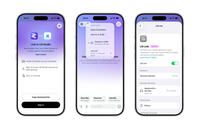
Anthropic's Fable 5 model is back for EU users and Sonnet 5 went live as well
Anthropic has announced that the Fable 5 model is available again for Claude users and the Sonnet 5 model is also live in Europe. The company is currently notifying eligible users of the model's availability via in-app message.